1회 정보처리기사 실기 해설
1번 문제
class Static{
public int a = 20;
static int b = 0;
}
public class Main{
public static void main(String[] args) {
int a;
a = 10;
Static.b = a;
Static st = new Static();
System.out.println(Static.b++);
System.out.println(st.b);
System.out.println(a);
System.out.print(st.a);
}
}Static 클래스에는 2개의 정수 변수가 있음. 인스턴스 변수 a는 초기 값 20. 정적 변수 b는 초기 값 0.
main 메소드에서 정적 변수 a가 선언 되고 값이 10이 할당 됨.
Static 클래스의 인스턴스가 생성되어 참조 변수 st에 할당 됨
System.out.println(Static.b++); => Static 클래스 정적 변수 b값을 출력하고 그 값을 1 증가 시킴. 10.
System.out.println(st.b); => b값이 증가되어서 11
System.out.println(a); => 로컬 변수 a값 10이 출력
System.out.print(st.a); => Static 클래스의 인스턴스인 인스턴스 변수 a의 값을 출력함. 20이 출력.
10
11
10
202번 문제
#include <stdio.h>
int main(){
char a[] = "Art";
char* p = NULL;
p = a;
printf("%s\n", a);
printf("%c\n", *p);
printf("%c\n", *a);
printf("%s\n", p);
for(int i = 0; a[i] != '#include <stdio.h>
int main(){
char a[] = "Art";
char* p = NULL;
p = a;
printf("%s\n", a);
printf("%c\n", *p);
printf("%c\n", *a);
printf("%s\n", p);
for(int i = 0; a[i] != '\0'; i++)
printf("%c", a[i]);
}
'; i++)
printf("%c", a[i]);
}
첫번째 printf 에서는 문자 배열 a에 저장된 문자열을 출력. %s (string) 이므로 Art
두번째 printf 에서는 포인터 p가 가리키는 문자를 출력. 문자열 Art의 첫 번째 문자인 A
세번째 printf 에서는 문자 배열 a의 첫 번째 요소의 값을 출력, A
네번째 printf에서는 포인터 p가 가리키는 문자열을 출력, Art
for 루프문에서는 \0에 도달할 때까지 a 배열의 각 문자를 반복해서 출력함. 참고로 \n은 없기 때문에 줄바꿈 없이 출력됨. Art
출력 결과:
Art
A
A
Art
Art3번 문제
#include <stdio.h>
int main(){
char* a = "qwer";
char* b = "qwtety";
for(int i = 0; a[i] != '#include <stdio.h>
int main(){
char* a = "qwer";
char* b = "qwtety";
for(int i = 0; a[i] != '\0' ; i++){
for(int j = 0; b[j] != '\0'; j++){
if(a[i] == b[j]) printf("%c", a[i]);
}
}
}
' ; i++){
for(int j = 0; b[j] != '#include <stdio.h>
int main(){
char* a = "qwer";
char* b = "qwtety";
for(int i = 0; a[i] != '\0' ; i++){
for(int j = 0; b[j] != '\0'; j++){
if(a[i] == b[j]) printf("%c", a[i]);
}
}
}
'; j++){
if(a[i] == b[j]) printf("%c", a[i]);
}
}
}main 함수에서 두 개의 문자 포인터 a, b가 선언되고 각각 문자열 “qwer”, “qwtety” 을 가리키도록 초기화됨
외부 루프와 내부 루프는 포인터 a와 b가 가리키는 문자열의 각 문자를 반복함. a를 기준으로 공통된 문자만 출력하므로
qwe 가 출력됨
4번 문제
– 해당 설명과 관련한 용어
- 비동기적 web application의 제작을 위해 JavaScript와 XML을 이용한 비동기적 정보 교환 기법
- 필요한 데이터만을 웹 서버에 요청해서 받은 후 클라이언트에서 데이터에 대한 처리를 할 수 있음
- 보통 SOAP이나 XML 기반의 웹 서비스 프로토콜이 사용되며, 웹 서버의 응답을 처리하기 위해서 클라이언트 쪽에서는 자바스크립트를 씀
- Google Map과 Google pages에서 사용한 기술에 기반하여 제작되었다.
AJAX(Asynchronous Javascript and XML)
5번 문제
- 회선교환 방식과 데이터그램 방식의 장점을 결합한 통신 기술
- 처음 패킷으로 최적의 경로를 고정하고 경로가 고정되면 그 다음은 패킷으로 나누어 고속으로 전송할 수 있다.
- 통신기술에는 ATM이 있으며, 정해진 시간 안이나 다량의 데이터를 연속으로 보낼 때 적합
가상회선
- 패킷교환 방식으로 동작하면서 IP 주소를 사용하는 인터넷을 의미
- 각 전송패킷을 미리 정해진 경로 없이 독립적으로 처리하여 교환하는 방식
- 특정 교환기의 고장 시 모든 패킷을 잃어버리는 가상회선과 달리, 그 경로를 피해서 전송할 수 있으므로 더욱 신뢰가 가능
- 짧은 메시지의 패킷들을 전송할 때 효과적이고 재정렬 기능이 필요
데이터그램
6번 문제
- 2 계층(데이터링크 계층)에서 구현되는 터널링 기술 중 하나
- L2F와 PPTP가 결합된 프로토콜로 VPN과 인터넷 서비스 제공자(ISP)가 이용
- IPsec을 함께 사용하면 PPTP 보다 훨씬 안전하지만 보안보다 익명화에 더 적합
L2TP
7번 문제
- 네트워크 상의 다른 컴퓨터에 로그인하거나 원격 시스템에서 명령을 실행하고 다른 시스템으로 파일을 복사할 수 있도록 해주는 응용 프로그램 또는 그 프로토콜을 가리킨다.
- 보안 접속을 통한 rsh, rcp, rlogin, rexec, telnet, ftp 등을 제공하며, IP spoofing 을 방지하기 위한 기능을 제공한다
- 기본 포트는 22번
SSH (Secure Shell)
8번 문제
(1)
- 이메일, 공유폴더 p2p네트워크를 이용해서 스스로 전파
- 자가 복제 가능하다
웜(worm)
(2)
- 사용자가 의도치 않는 소스코드 속에 숨어 있음.
- 감염된 후에 스스로를 복제하는 능력은 없다
트로이목마
(3)
- 자기 복제 능력이 있음
- 자가 전파는 되지 않음
바이러스
9번 문제
#include
int main() {
int input = 101110;
int di = 1;
int sum = 0;
while (1) {
if(input == 0) break;
else {
sum = sum + (input {1} {2}) * di;
di = di * 2;
input = input / 10;
}
}
printf("%d", sum);
return 0;
}{1} -> %
{2} -> 10
10번 문제
- TCP/IP에서 IP 패킷을 처리할 때 발생되는 문제를 알려주는 프로토콜
- ping 명령어를 통한 해당 패킷을 연속적으로 계속 보내어 서버의 요청에 응답으로 인한 다른 작업을 하지 못하도록 하는 공격이 해당 Flooding이다
ICMP
11번 문제
객체의 대리인, mediate라고도 함. 을 이용하여 원래 객체 작업을 대신 처리하는 패턴을 무엇이라고 하는가
Proxy
12번 문제
(1)
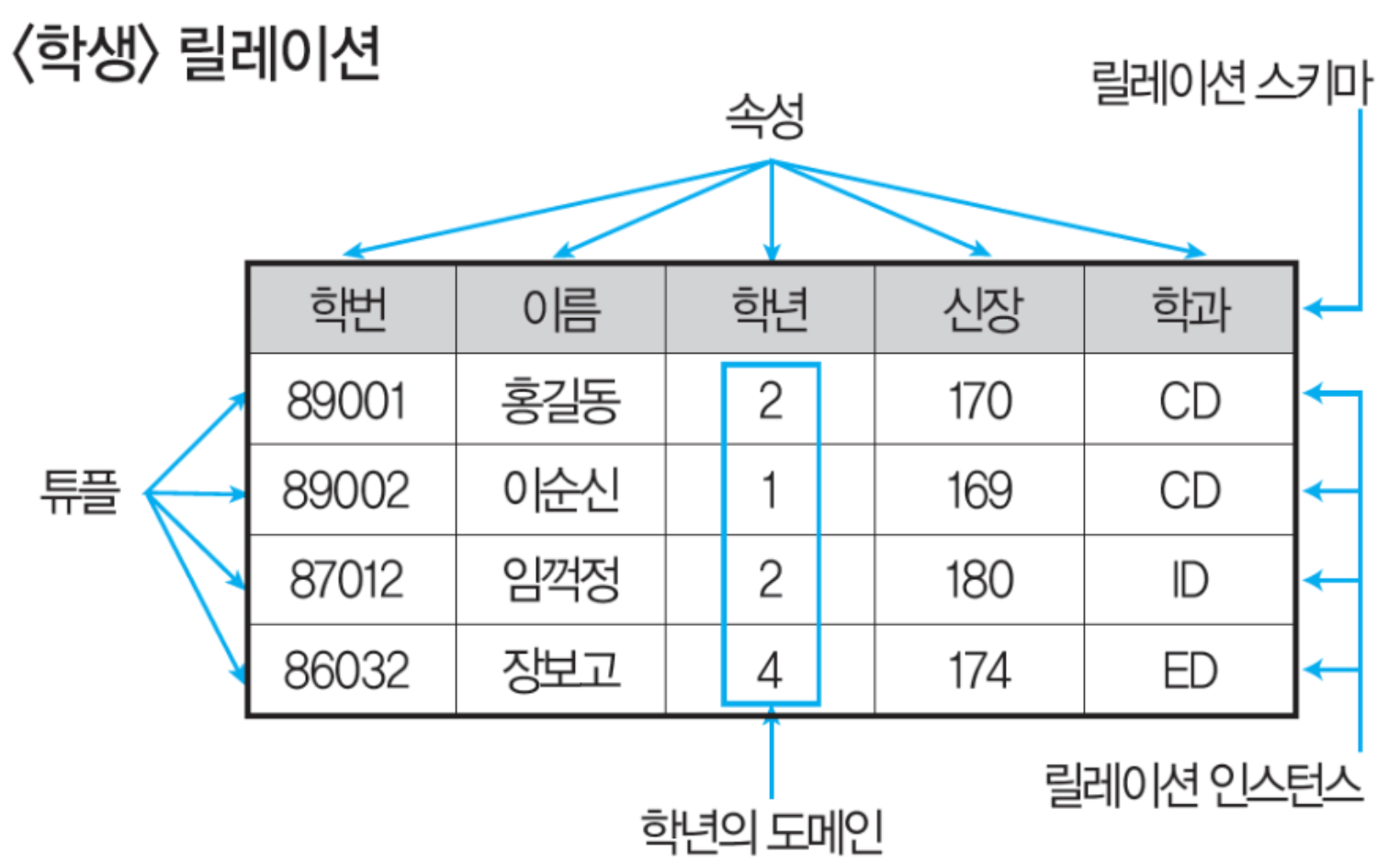
- 테이블에서의 행을 가리킴. 중복허용
Tuple
(2)
- 릴레이션의 외연Relation Extension 이라고도 한다
Relation Instance
(3)
- 특정 데이터 집합의 unique한 값의 개수
Cardinality
(참조)

relation : 데이터를 2차원 표로 나타낸 것
relation schema : 데이터 구조
relation instance: 해당 구조에 들어가 있는 값
tuple: 각각의 행을 의미
domain : 각 속성이 가지는 값의 집합
degree : 속성의 수 : 학번, 이름, 학년, 신장, 학과 총 5개
13번 문제
delete from 학생 wherer 이름=”민수”;
14번 문제
#include
void swap(int a[], int idx1, int idx2) {
int t = a[idx1];
a[idx1] = a[idx2];
a[{1}] = t;
}
void sort(int a[], int len) {
for(int i=0; i
for(int j=1; j
if(a[j] > a[j+1])
swap(a, j, j+1);
}
}
}
int main() {
int nx = 5;
int a[] = {5, 15, 7, 20, 11};
sort(a, {2});
for(int i=0; i
printf("%d ", a[i]);
}
}{1} -> idx2
{2} -> nx
15번 문제 python set 문제
a = {'한국', '중국', '일본'}
a.add('베트남')
a.add('중국')
a.remove('일본')
a.update({'홍콩', '한국', '태국'})
print(a)중복값 제거하는 문제. 해당 문제 풀이는 Pass
16번 문제
select 과목 이름, min(점수) as 최소점수, max(점수) as 최대점수
from 성적
group by 과목이름
having avg(점수) >=90;
17번 문제
abstact class Vehicle {
String name;
abstract public String getName(String val);
public String getName() {
return "Vehicle name: " + name;
}
}
class Car extends Vehicle {
public Car(String val) {
name=super.name=val;
}
public String getName(String val) {
return "Car name:" + val;
}
public String getName(byte val[]) {
return "Car name:" + val;
}
}
public class Main {
public static void main(String[] args) {
Vehicle obj = new Car("Spark");
System.out.println(obj.getName());
}
}해석:
public class main 을 보면 이 메소드는 이름이 “Spark”인 Car 클래스의 인스턴스를 생성하고 이것을 참조 변수인 Vehicle에 할당함.
그런 다음 이 객체에서 getName() 메소드를 호출 함. Car 클래스의 인스턴스를 생성할 때 name=super.name=val 이므로 name은 Spark인 채로 Vehicle 상위 클래스에 할당되고 getName()을 하면 Vehicle name: Spark가 됨…
출력값:
Vehicle name: Spark
18번 문제
(1)
- 서브 스키마라고 함
- 하나의 데이터베이스 시스템에는 여러개의 외부 스키마가 존재
- 하나의 외부 스키마를 여러 개의 응용 프로그램 혹은 사용자가 공유
외부 스키마
(2)
- 데이터베이스 파일에 저장되는 데이터의 형태
- 기관이나 조직체의 관점에서 데이터베이스를 정의
개념 스키마
(3)
- 물리적인 저장장치 입장에서 데이터가 저장되는 방법
- 저장 데이터 항목의 표현방법, 내부 레코드의 물리적 순서, 인덱스 유/무 등을 나타냄
내부 스키마
19번 문제
화이트박스 분기 커버리지

1 2 3 4 5 6 1
1 2 4 5 6 7
20번 문제
class Parent {
int x = 100;
Parent() {
this(500);
}
Parent(int x) {
this.x = x;
}
int getX() {
return this.x;
}
}
class Child extends Parent {
int x = 1000;
Child() {
this(5000);
}
Child(int x) {
this.x = x;
}
}
public class Main {
public static void main(String[] args) {
Child obj = new Child();
System.out.println(obj.getX());
}
}해석:
이 메소드는 Child 클래스의 인스턴스를 생성 obj. 인수가 없는 생성자가 호출됨. Child() 이기 때문에 this(5000)을 호출. 그런데 이 생성자는 x 필드에 값을 할당하기 전에 먼저 Parent 클래스의 인수가 없는 생성자를 호출 Parent() . this(500)을 호출하여 이 생성자는 x 필드에 500을 할당. 코드에서 getX() 메소드를 호출하면 이건 Parent 클래스에서 정의된 x를 의미함. Child에서는 x는 5000임. getX()는 Parent 클래스의 x를 호출하기 때문에 따라서 Parent에서 인수 없이 불러진 this(500) 이 x 값으로 할당되어, 부모 클래스에서 정의된 x필드의 값을 출력하니 500임.
new Child();로 해당 자식 객체가 생성될 때 부모 클래스의 생성자가 먼저 호출되어 x값이 할당하는 것…
출력:
500