용어 정리 1 : alpha level (α) , 유의 수준이란
level of significance (유의 수준) 또는 alpha 수준이라고도 한다.
가설을 검증할 때, 해당 표본 집단의 확률의 높고 낮음을 정하는 기준을 설정하는 것이라고 할 수 있다.
α = .05 (또는 5%로 표시하기도 함)
α = .01 (1%)
α = .001 (0.1%)
를 보통 기준으로 설정한다.
예를 들어 95%를 신뢰도가 있다고 할 때, 그건 유의 수준을 α = .05 로 설정했다 뜻이다.
귀무가설을 95%의 신뢰도에서 기각했다고 한다면, 해당 표본의 평균 값이 나올 확률이 95%를 벗어난 5%에 들어간 이상치란 뜻이기도 하다.
그 이상치는 해당 값이 일어날 확률이 매우 낮다 라는 의미와 동일하다
5% = 해당 확률이 일어날 확률이 매우 낮음
용어 정리 2: critical region
그럼 저 5%에 해당하는 영역을 기각역(critical region) 이라고 부른다.
5%의 확률을 가진, 매우 일어나기 힘든 확률을 가진 값을 표현한다.
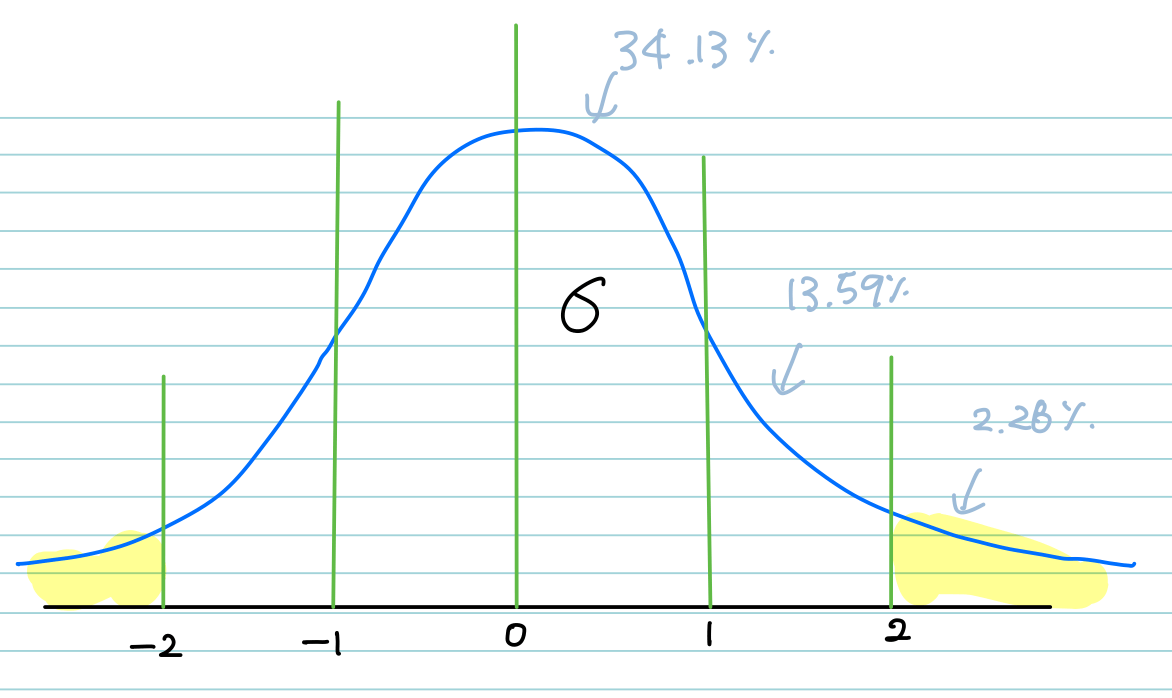
정규분포곡선(Normal Distribution) 을 보면 해당 기각역을 이해하기 쉽다.
하단에 노트에 그린 게 Normal distribution이고, 정규화(z-score)을 거쳐서 중간의 x축 값(µ)을 0을 기준으로 만들고,

양측으로 1일 때, -1일 때, 2일 때, -2일 때를 그리면 대칭이 되는 형태로 나타난다. 이 때 µ가 +2 이상이거나 -2 이하인 경우는 거의 일어나지 않는다.
가운데 값을 0으로 만드는 것을 표준화 과정이라고 하는데, 이 표준화 과정에서 +-2 인 확률은 좌측은 2.28%, 우측은 2.28%. 즉 대략 4.56% 정도이다.
예를 들어, IQ 검사에서 해당 값도 정규 분포 곡선을 그리는데 +1 이 115, +2가 130 이다. 즉 IQ가 130이 넘는다면 저기 2.28% 확률. 있을 수 있는 확률이 아닌 것이다. 다른 말로 하면 “비정상(abnormal)” 이다. 마찬가지로 -2 이하도 동일함.
잡다한 이야기…그러니까 어떤 방송에서 지능지수가 130이 넘었다라고 떠드는 건 몇 프로 안되는 사람을 흔히 볼 수 있는 것처럼 비춰서 만드는 건데. 방송이 얼마나 비정상을 정상처럼 비춰주는지 확률을 통해서 이해할 수 있다. 지나치게 자주 접하다보니 저 비정상이 정상처럼 보이는 기적을 보게 된다. 인스타도 마찬가지….난 왜 이런가 하고 있을 필요가 없다. 방송이나 가십은 특이하고 이상하니까 시청률이 되니 그걸 비출 뿐. 정상을 비추지 않는다. 흥미롭고 재밌게만 보이는 건 비정상일 수 있다는 거.

아무튼 기각역(critical region)에 들어가는 게 저기 양측의 “일어날 확률이 낮은” 영역의 값을 표시해둔 거라고 보면 된다.
5%라면 표준화 시킨 z-score 일 때는 +- 1.96 값이 된다.
표준화 했을 때 값이 만약 2(z = 2)가 나왔다면 해당 값은 일어날 확률이 낮은 기각역(critical region)에 있는 것이고,
95%의 신뢰도로 해당 귀무 가설을 기각할 수 있다.

참고) z-score 값 내는 법, 표준화 시키는 법은
표준화 시키는 건 표본 평균 – 모집단 평균 / 모집단의 표준 오차 이다.

모집단의 표준 오차는 = 모집단의 모편차 / 총 갯수의 루트를 씌운 값… 그럼 가운데가 0이고 나머지가 1, 2로 나뉘어 볼 수 있다.

마지막으로,
p-value : probability value 는,
해당값이 일어날 확률이다.
만약 z=2.45라고 하자. 특정한 값을 측정하고 해당 값을 표준화 했더니 z값이 2.45, 해당 값이 일어날 확률이 p=.0142가 나왔다.
정확한 exact p값은 저 위의 공식… 를 통해서 해당 곡선의 y값. frequency를 구하면 된다. 지금까지 구한 건 적분값인 넒이로 확률을 구했다. 보통은 컴퓨터를 통해 구하기 때문에 사실 중요하지도 않고, 잊어버려도 되는데, 그 frequency를 구하는 프로그램을 만드는 사람은 이걸 기억해야 한다 :->….

이 그래프를 보면 해당 값은 기각역(critical region)에 들어가니 0.05의 확률 보다 낮게 나타난다. 귀무가설을 기각할 수 있는 p < a 영역이다,
그래서 글을 쓰면
해당 값은 유의미하다(z=2.45, p < 0.05)라고 쓸 수 있다.
*
*오류나 잘못된 설명이 있을 수 있음!